6 Common Auto-GPT Installation Issues and How to Resolve Them
Llama ˈLocal-Ization’ Guide: How to Install and Use It Yourself
Meta released Llama 2 in the summer of 2023. The new version of Llama is fine-tuned with 40% more tokens than the original Llama model, doubling its context length and significantly outperforming other open-sourced models available. The fastest and easiest way to access Llama 2 is via an API through an online platform. However, if you want the best experience, installing and loading Llama 2 directly on your computer is best.
With that in mind, we’ve created a step-by-step guide on how to use Text-Generation-WebUI to load a quantized Llama 2 LLM locally on your computer.
 NeoDownloader - Fast and fully automatic image/video/music downloader.
NeoDownloader - Fast and fully automatic image/video/music downloader.
Why Install Llama 2 Locally
There are many reasons why people choose to run Llama 2 directly. Some do it for privacy concerns, some for customization, and others for offline capabilities. If you’re researching, fine-tuning, or integrating Llama 2 for your projects, then accessing Llama 2 via API might not be for you. The point of running an LLM locally on your PC is to reduce reliance onthird-party AI tools and use AI anytime, anywhere, without worrying about leaking potentially sensitive data to companies and other organizations.
With that said, let’s begin with the step-by-step guide to installing Llama 2 locally.
 PDF application, powered by AI-based OCR, for unified workflows with both digital and scanned documents.
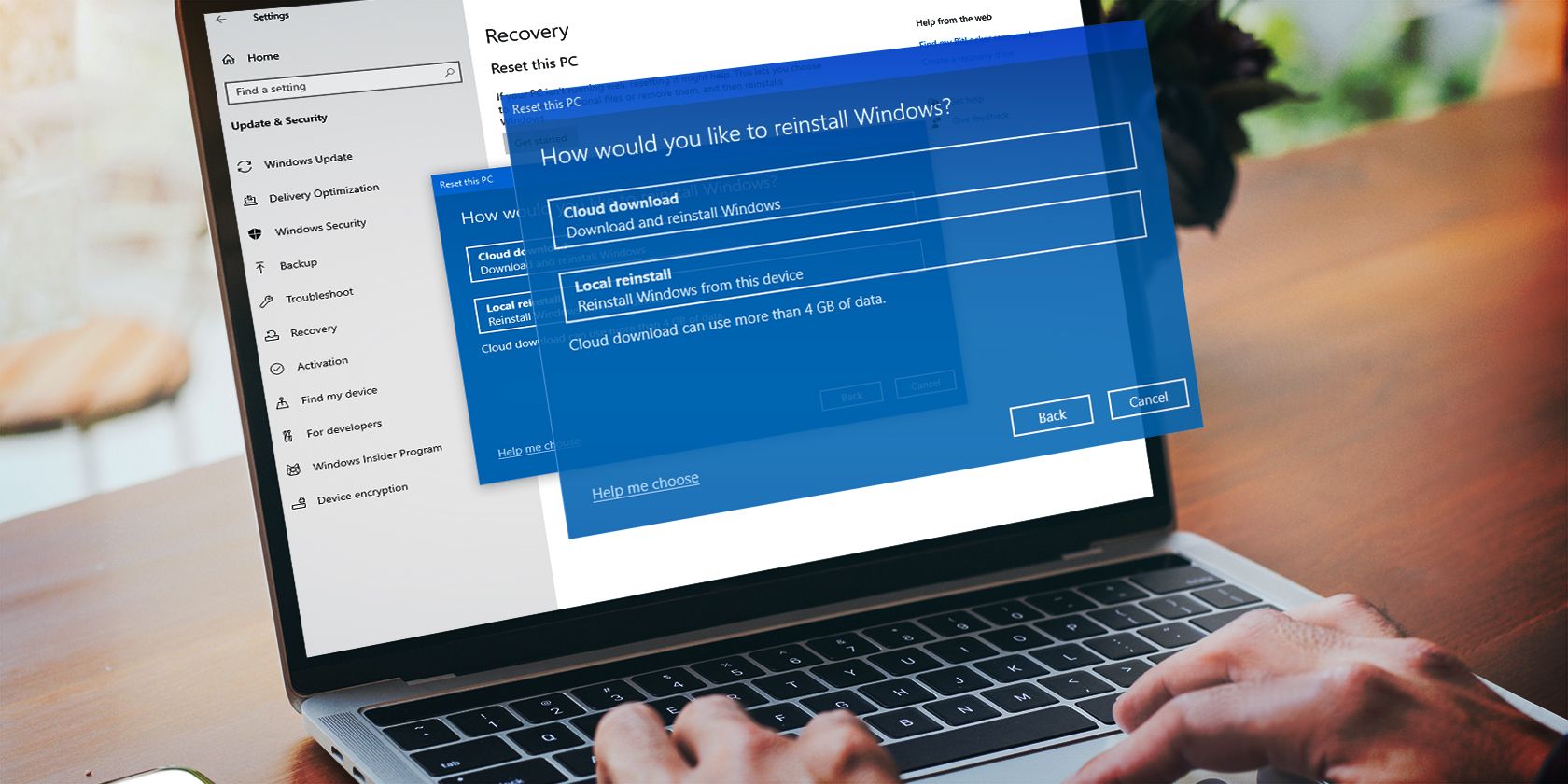
PDF application, powered by AI-based OCR, for unified workflows with both digital and scanned documents. Step 1: Install Visual Studio 2019 Build Tool
To simplify things, we will use a one-click installer for Text-Generation-WebUI (the program used to load Llama 2 with GUI). However, for this installer to work, you need to download the Visual Studio 2019 Build Tool and install the necessary resources.
Download: Visual Studio 2019 (Free)
- Go ahead and download the community edition of the software.
- Now install Visual Studio 2019, then open the software. Once opened, tick the box onDesktop development with C++ and hit install.

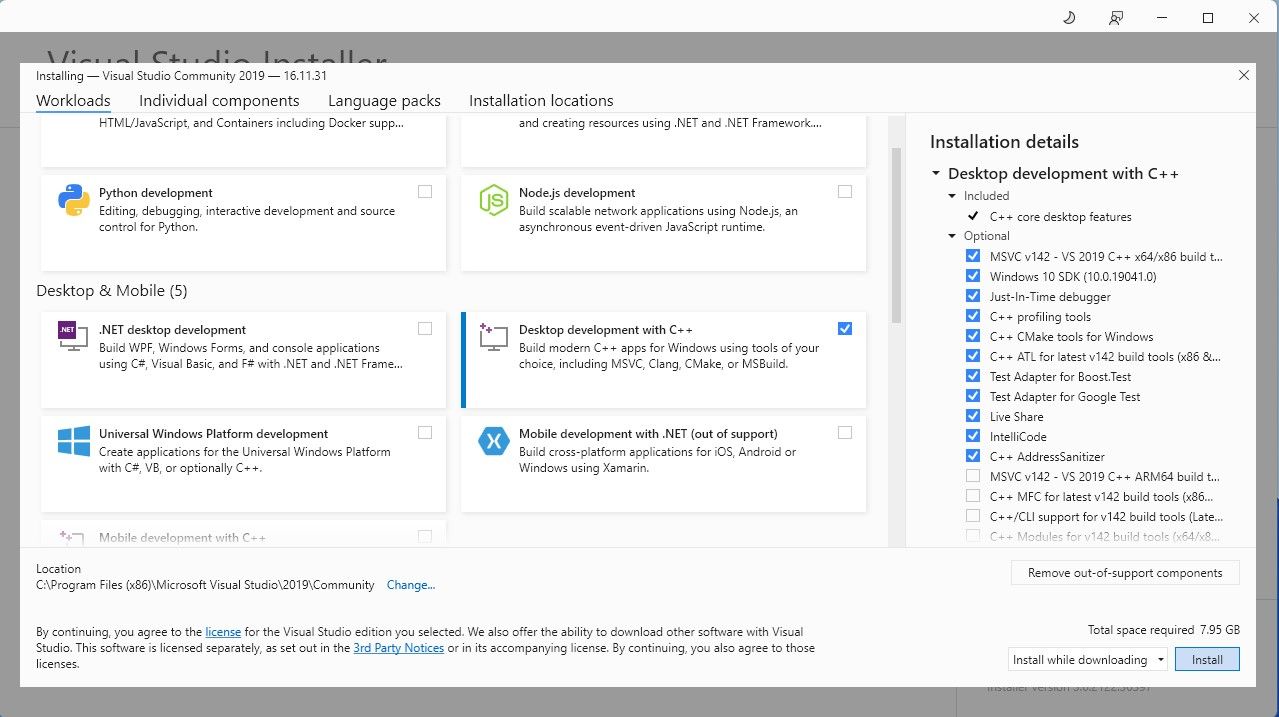
Now that you have Desktop development with C++ installed, it’s time to download the Text-Generation-WebUI one-click installer.
 CollageIt Pro
CollageIt ProStep 2: Install Text-Generation-WebUI
The Text-Generation-WebUI one-click installer is a script that automatically creates the required folders and sets up the Conda environment and all necessary requirements to run an AI model.
To install the script, download the one-click installer by clicking onCode >Download ZIP.
Download: Text-Generation-WebUI Installer (Free)
- Once downloaded, extract the ZIP file to your preferred location, then open the extracted folder.
- Within the folder, scroll down and look for the appropriate start program for your operating system. Run the programs by double-clicking the appropriate script.
- If you are on Windows, selectstart_windows batch file
- for MacOS, selectstart_macos shell scrip
- for Linux,start_linux shell script.
- Your anti-virus might create an alert; this is fine. The prompt is just anantivirus false positive for running a batch file or script. Click onRun anyway .
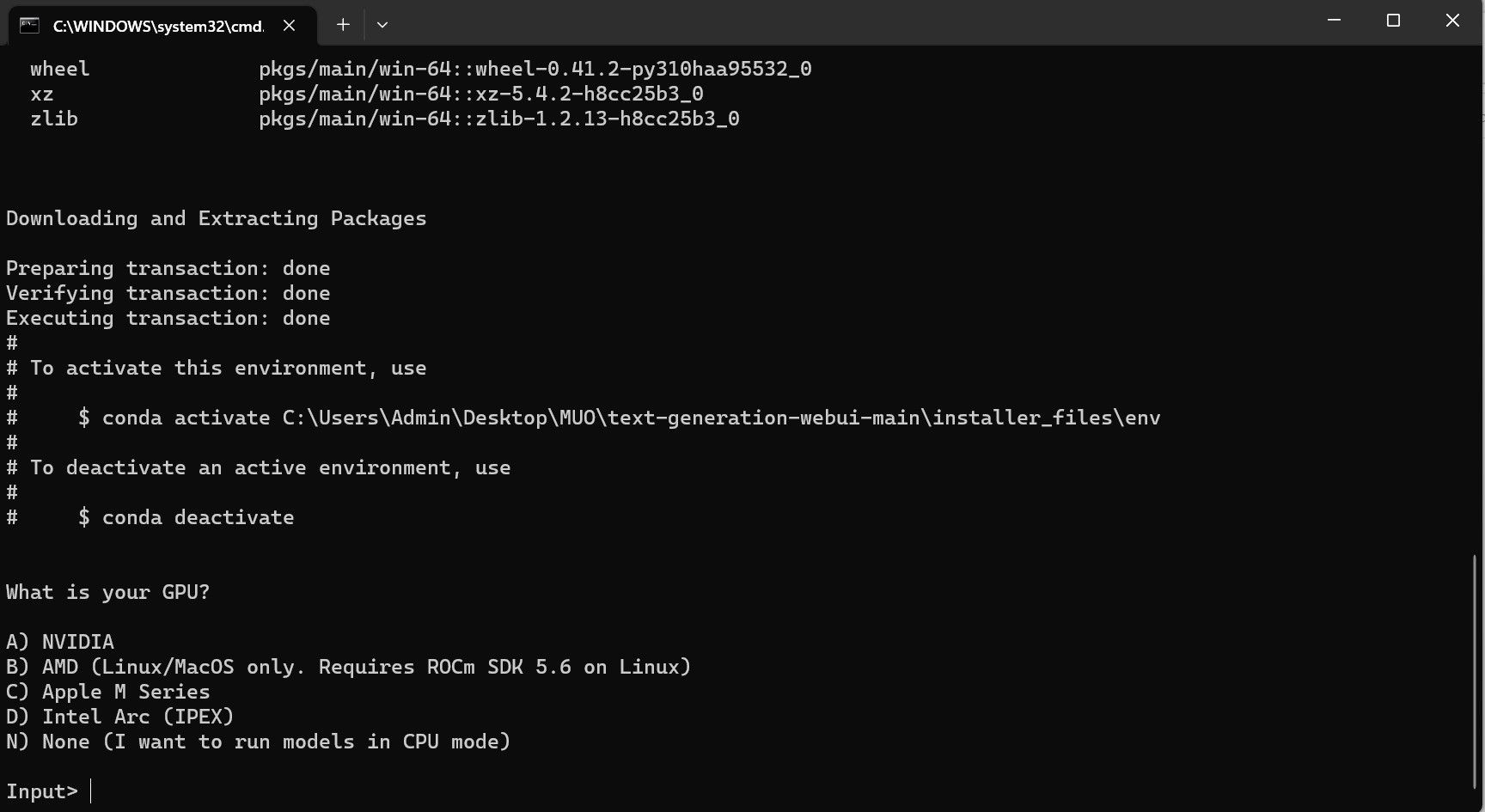
- A terminal will open and start the setup. Early on, the setup will pause and ask you what GPU you are using. Select the appropriate type of GPU installed on your computer and hit enter. For those without a dedicated graphics card, selectNone (I want to run models in CPU mode) . Keep in mind that running on CPU mode is much slower when compared to running the model with a dedicated GPU.
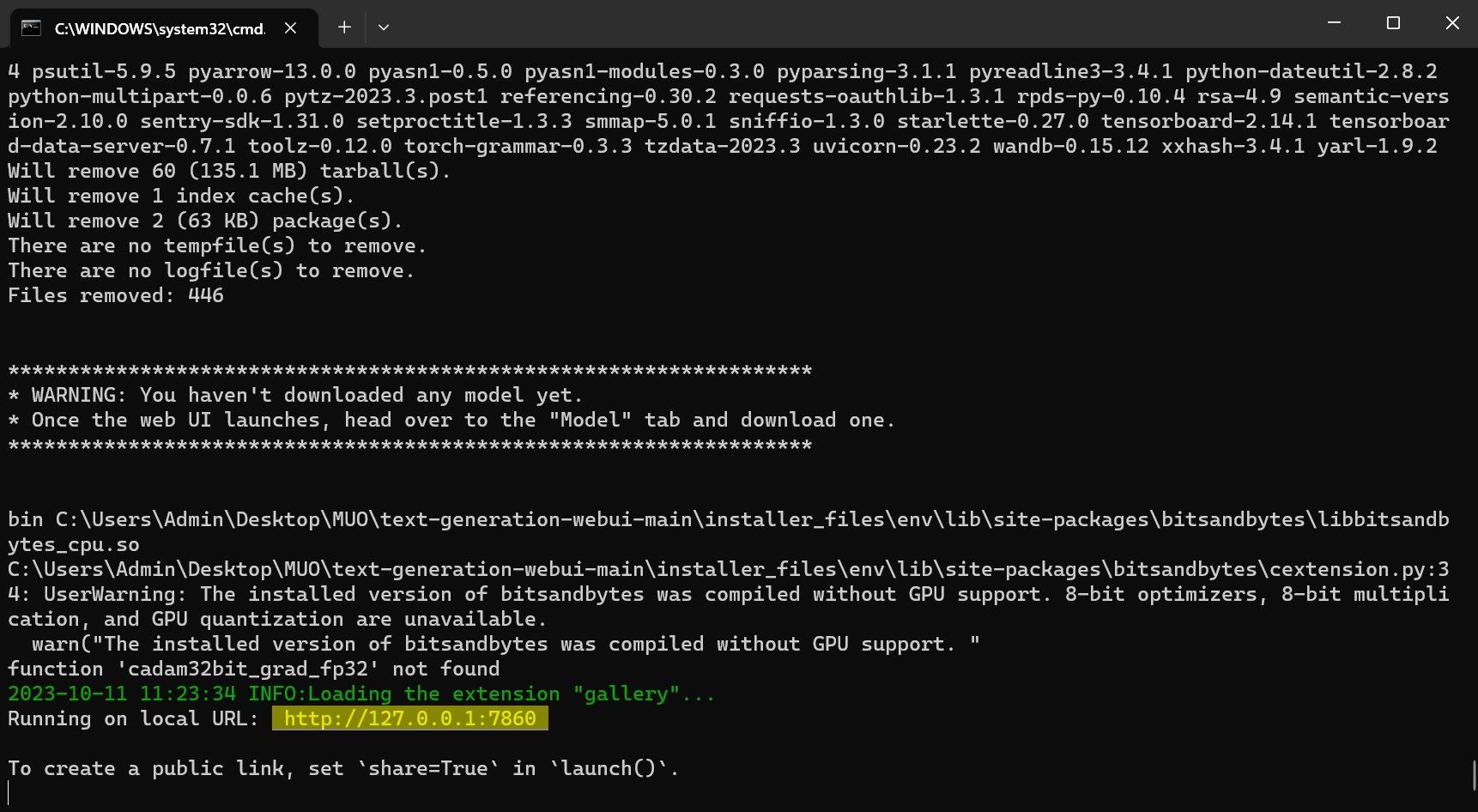
- Once the setup is complete, you can now launch Text-Generation-WebUI locally. You can do so by opening your preferred web browser and entering the provided IP address on the URL.
- The WebUI is now ready for use.
However, the program is only a model loader. Let’s download Llama 2 for the model loader to launch.
Step 3: Download the Llama 2 Model
There are quite a few things to consider when deciding which iteration of Llama 2 you need. These include parameters, quantization, hardware optimization, size, and usage. All of this information will be found denoted in the model’s name.
- Parameters: The number of parameters used to train the model. Bigger parameters make more capable models but at the cost of performance.
- Usage: Can either be standard or chat. A chat model is optimized to be used as a chatbot like ChatGPT, while the standard is the default model.
- Hardware Optimization: Refers to what hardware best runs the model. GPTQ means the model is optimized to run on a dedicated GPU, while GGML is optimized to run on a CPU.
- Quantization: Denotes the precision of weights and activations in a model. For inferencing, a precision of q4 is optimal.
- Size: Refers to the size of the specific model.
Note that some models may be arranged differently and may not even have the same types of information displayed. However, this type of naming convention is fairly common in theHuggingFace Model library, so it’s still worth understanding.

In this example, the model can be identified as a medium-sized Llama 2 model trained on 13 billion parameters optimized for chat inferencing using a dedicated CPU.
For those running on a dedicated GPU, choose aGPTQ model, while for those using a CPU, chooseGGML . If you want to chat with the model like you would with ChatGPT, choosechat , but if you want to experiment with the model with its full capabilities, use thestandard model. As for parameters, know that using bigger models will provide better results at the expense of performance. I would personally recommend you start with a 7B model. As for quantization, use q4, as it’s only for inferencing.
Download: GGML (Free)
Download: GPTQ (Free)
Now that you know what iteration of Llama 2 you need, go ahead and download the model you want.
In my case, since I’m running this on an ultrabook, I’ll be using a GGML model fine-tuned for chat,llama-2-7b-chat-ggmlv3.q4_K_S.bin.
After the download is finished, place the model intext-generation-webui-main >models .
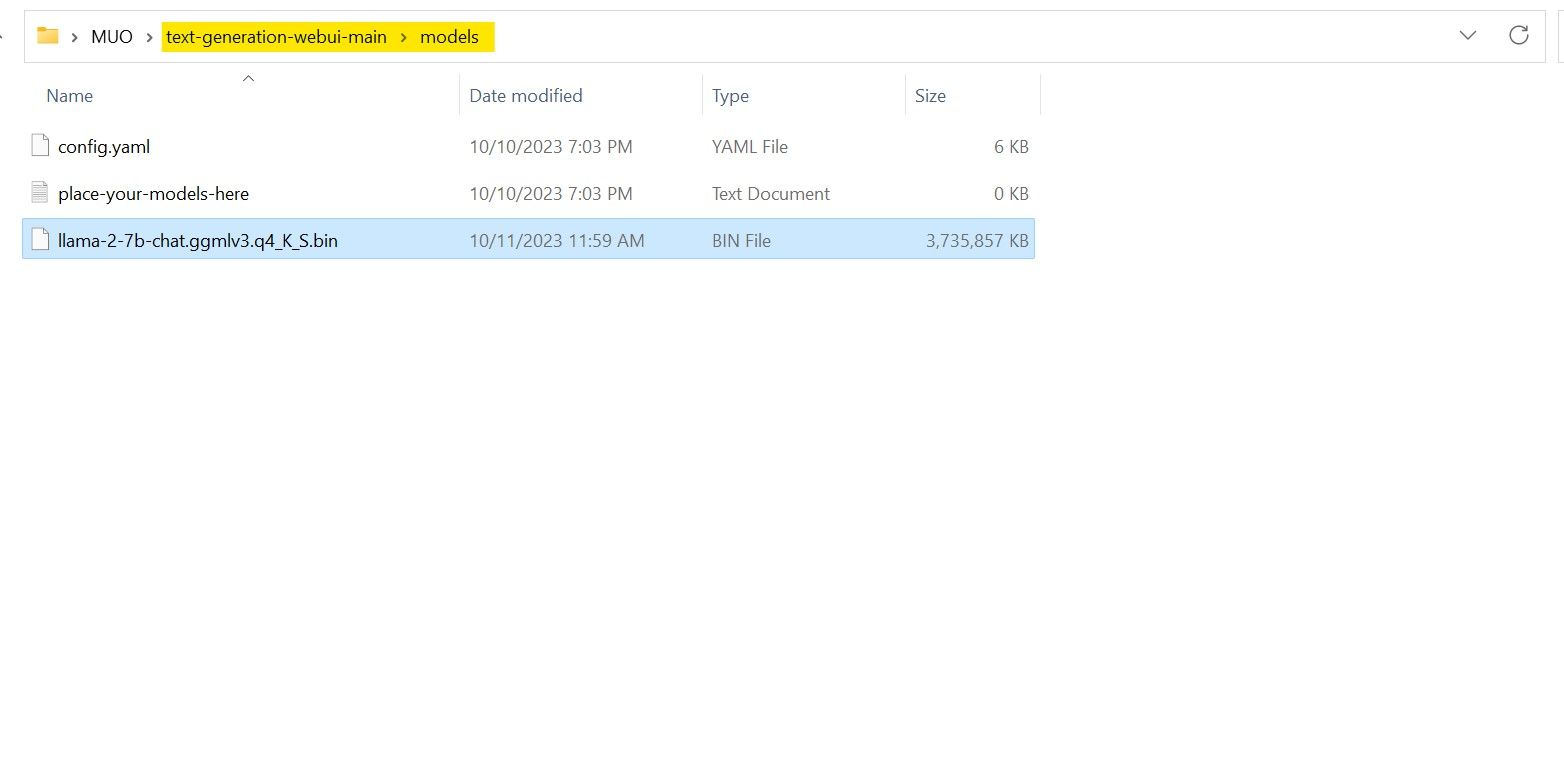
Now that you have your model downloaded and placed in the model folder, it’s time to configure the model loader.
 Forex Robotron Gold Package
Forex Robotron Gold PackageStep 4: Configure Text-Generation-WebUI
Now, let’s begin the configuration phase.
- Once again, open Text-Generation-WebUI by running thestart_(your OS) file (see the previous steps above).
- On the tabs located above the GUI, clickModel. Click the refresh button at the model dropdown menu and select your model.
- Now click on the dropdown menu of theModel loader and selectAutoGPTQ for those using a GTPQ model andctransformers for those using a GGML model. Finally, click onLoad to load your model.
- To use the model, open the Chat tab and start testing the model.
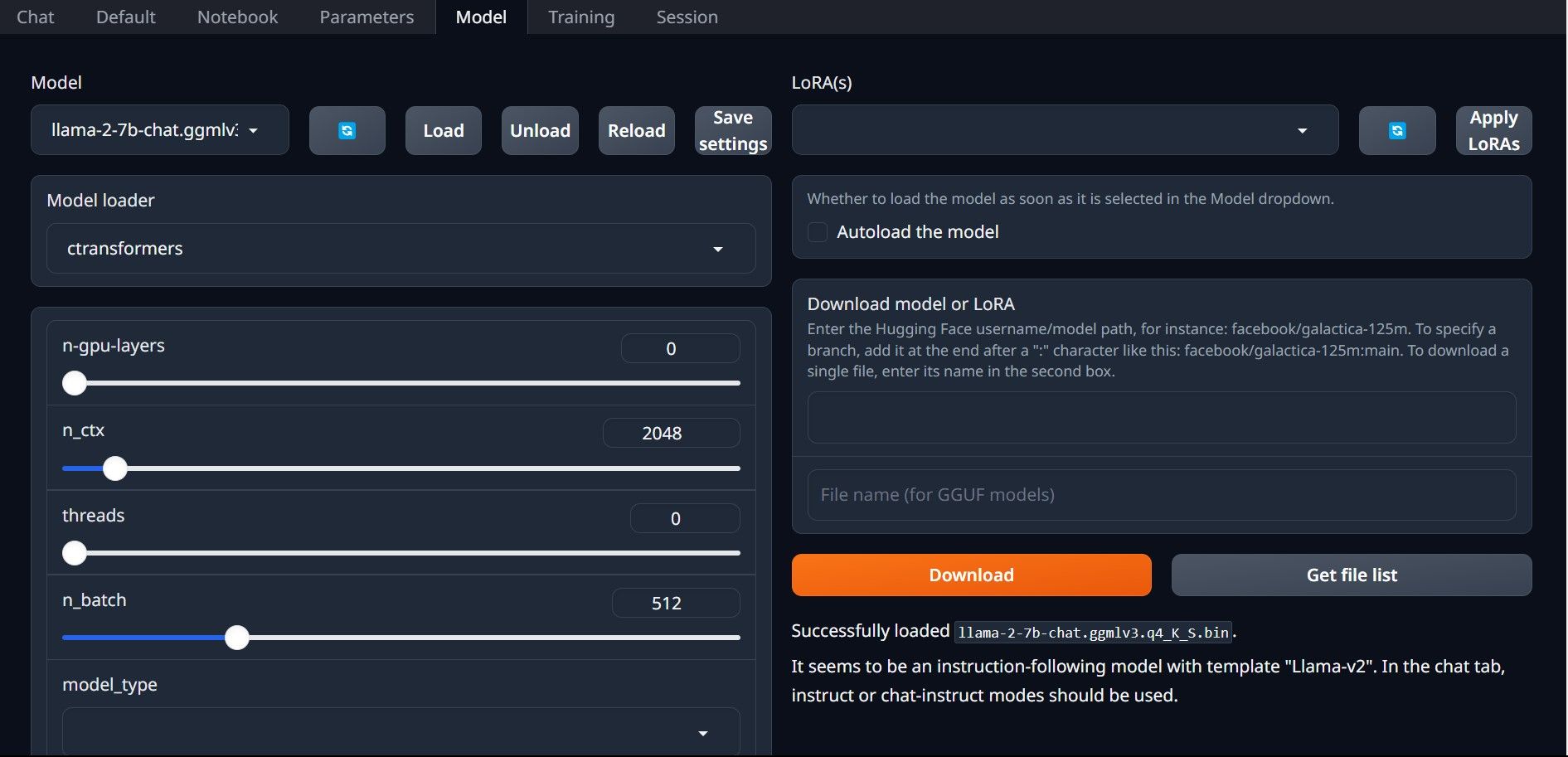
Congratulations, you’ve successfully loaded Llama2 on your local computer!
WPS Office Premium ( File Recovery, Photo Scanning, Convert PDF)–Yearly
Try Out Other LLMs
Now that you know how to run Llama 2 directly on your computer using Text-Generation-WebUI, you should also be able to run other LLMs besides Llama. Just remember the naming conventions of models and that only quantized versions of models (usually q4 precision) can be loaded on regular PCs. Many quantized LLMs are available on HuggingFace. If you want to explore other models, search for TheBloke in HuggingFace’s model library, and you should find many models available.
- Title: 6 Common Auto-GPT Installation Issues and How to Resolve Them
- Author: Jeffrey
- Created at : 2024-08-16 10:46:29
- Updated at : 2024-08-17 10:46:29
- Link: https://tech-haven.techidaily.com/6-common-auto-gpt-installation-issues-and-how-to-resolve-them/
- License: This work is licensed under CC BY-NC-SA 4.0.